
MVM - Minimal Viable Model
Written by • • 6 min readLLMs are often assumed to answer any AI need. However, they’re also extremely resource intensive. Minimal Viable Model explores how going small, rather than large, and going local-first instead of cloud-first, can unlock opportunities such as improved privacy, faster speeds and cost reduction.

The largest LLMs out there (GPT, Claude, Gemini, Llama, etc.) are sometimes assumed to be the answer to any, and every, AI need. However, they’re also extremely resource intensive. Their size can bring performance and latency issues, the energy required to train them can be challenging for organisations with sustainability targets, and they can be very expensive when applied at scale.
As Principal of Applied AI Technologies at Normally, my role is to explore solutions and approaches that balance doing good for people, for the planet and for the organisations we work with. One of our recent explorations set out to uncover the opportunities of going small - rather than large, going local-first - instead of cloud-first, and comparing the quality of results more specific AI models have to offer. We call this approach the Minimal Viable Model (MVM).
Our MVM is an approach to using AI in a mindful manner that focuses on delivering user & business value by using the most appropriate, smallest required model (be it a small LLM, tiny embeddings model or other ML model) to achieve a desired outcome.
Enabled by the proliferation of open-source libraries and models (especially in the Javascript world), the MVM approach brings numerous benefits to users and organisations:
- Improved privacy (Smaller, more specific models can run locally)
- Faster speeds (Large LLMs can take a long time to process data)
- Cost reduction (Code running in the client reduces infrastructure cost)
- Outcome consistency & observability (More specific models can often be more deterministic)
Some numbers

Energy cost of training GPT4
The estimated energy consumed to train GPT4 is 57,045 GWh. An equivalent number of gigawatt hours could power all homes in London with energy for over a year (data source: LEGGI 2021).*
The LLMs are not always performative
At the time of writing, GPT-4o sentiment analysis response time was 2000x slower, compared to a locally run javascript model with a similar quality of outcome.**
GenAI workloads are expensive
We estimate an established social media network could spend around $1,100,000 per day on basic content moderation using a commercial LLM (sentiment analysis and simple word banning).***
Introducing MVM in our AI applications

Embedding artificial intelligence in applications is best thought of as a chain of different tools, models and techniques strung together, each with a specific task. This builds a whole that is bigger than the sum of its parts - rather than a single model or a request that magically solves everything.
Even the most complex AI assistants, agents, or chains are usually a combination of cleverly engineered prompts, responses, parsing functions and a whole lot of connecting code that strings them together.
Applying the MVM approach means replacing some of the largest and most resource-intensive models - usually the LLM part of the chain - with smaller, purpose-built and specifically trained ones. We have found that rather than leading to a reduction in quality, this approach unlocks many benefits.
Local first, privacy protecting
The main advantage of using a smaller model is that they can often be run locally, either in a browser, app or within a company’s infrastructure.
This means data doesn’t need to be sent to a third party for processing, which helps boost privacy and protects IP. In some cases, such as on-device models, data can be processed without an internet connection at all.
For example, a NHS Trust wanting to build a better search function for its patient data using vectors might be prohibited from sending this data to a third party. However, using a smaller, local embeddings model and a self-hosted Postgres database with pgvector extension, could provide very similar quality search results.
Low latency
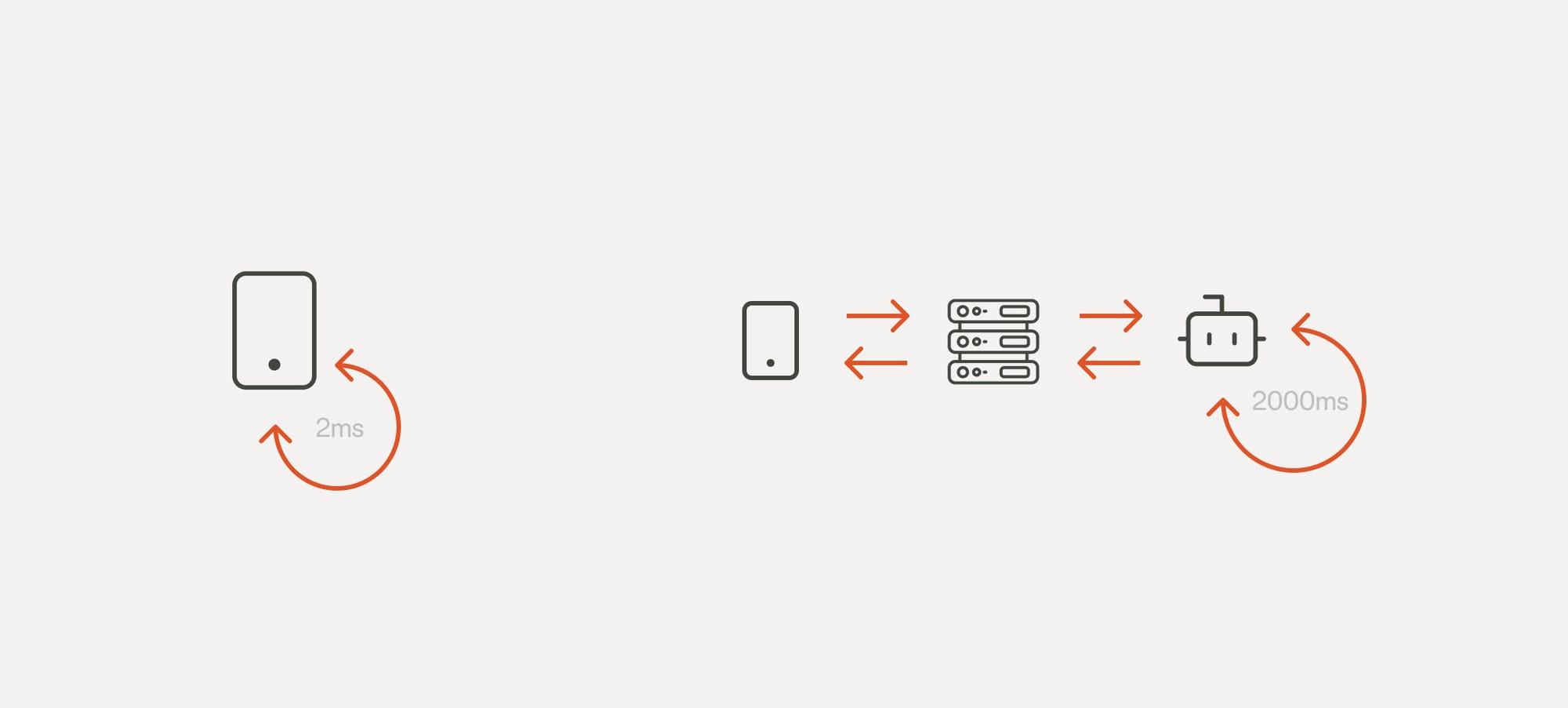
The second benefit of the MVM approach is the performance that comes with smaller models. We can often reach a latency of single-digit milliseconds, compared to 2000ms for LLMs, which makes the MVM approach ideal for applications where real-time feedback is required. Real-time sentiment analysis, financial calculations, video interpretations, and live processing could all benefit from this approach.**
Cost reduction
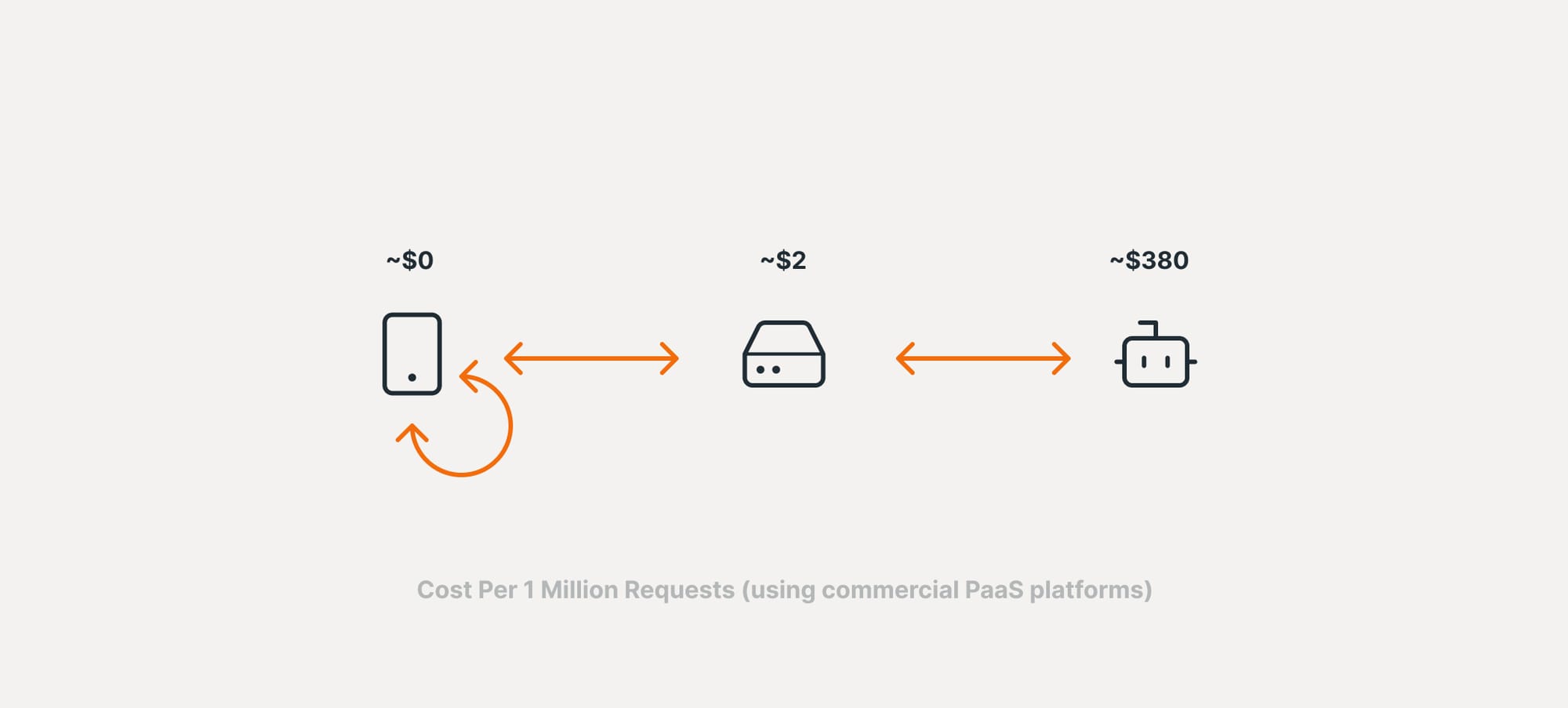
Using LLMs at scale can quickly become cost-prohibitive for organisations while running smaller, local models is practically free.
One example calculation: imagine a global social network using LLMs for sentiment analysis in its content moderation. We found that the MVM approach could reduce sentiment analysis costs from over $1,000,000 per day to around $5,800 – a saving of 99.42%.***
With rising serverless architectures and pay-per-second of compute use models, the MVM approach could drastically reduce the cost and latency of doing the round trip all the way to LLM endpoint and back. These can be orders of magnitude smaller than even provisioning a local VPS machine(s) with LLMs running on it.
Quality, consistency, control, and observability
Unlike LLMs, which are probabilistic in their outputs, local models and algorithms can also be deterministic, meaning they will produce the same result given the same input. This is extremely useful when dealing with numeric data and calculations or when we want to prevent any LLMs “hallucinating”. A great example of this is the ARIMA (Autoregressive integrated moving average) set of models used for traditional time series forecasting in finance.
Smaller models and algorithms (for example parametric recommendation engines) can also provide us with complete control over the parameters and weights used to make decisions. This gives greater control, as well as the ability to observe the model’s decision-making process.
The right model for the right job: in defence of (larger) LLMs
Quality
Certain tasks, such as sentiment analysis, benefit from a larger model. The more training data and knowledge, the higher the quality of the detection of meaning or opinion. For example, a LLM would easily detect sarcasm, whereas a local model would struggle.
Versatility
Probably the best argument for using LLMs is their ability to generalise and perform a variety of tasks with a relatively small amount of development work required. Instead of spending hours writing code that solves edge cases, we can tweak the prompt.
When prototyping, LLMs allow us to ‘mock-up’ complex API endpoints and capabilities with just simple engineering of prompts. In production they can be used to parse a much more complex set of unstructured data than a predefined regex code would.
LLMs can reason, plan, evaluate, and generate. All of this makes them incredibly powerful and disruptive, and they’re only getting better. I would not bet against them, especially when used mindfully.
Summary
Much of the concern and criticism of AI we are seeing at the moment relates specifically to the challenges with the largest LLMs, particularly when used as a proverbial sledgehammer. Considering the MVM approach as an alternative is one way to navigate forward in a balanced, pragmatic and mindful way. We would love to hear from anyone trying something similar, or different!
Peter Koraca is Principal of Applied AI Technologies at Normally.
Footnotes
*Energy consumption
The carbon footprint of GPT4: https://towardsdatascience.com/the-carbon-footprint-of-gpt-4-d6c676eb21ae
LEGGI London Energy consumption data: https://data.london.gov.uk/dataset/leggi
**Sentiment analysis prototype
We built a sentiment analysis POC using the Natural javascript library (AFINN vocabulary set) and pinned it against GPT4o for comparison. We measured how long it took our JS API endpoint to return a result vs OpenAI’s LLM’s interpretation.
***Cost
We used commercially available pricing data from OpenAI (LLM vendor) and Vercel (Hosting/Edge provider) to arrive at the numbers.
We calculated the LLM cost as an average of 8 input tokens would be used per request and 10 for output (optimistically). Cost per input token at the time of writing was $0.00001, cost per output token: $0.00003. Calculating these for 2,900,000,000 requests per day gives us the cost of $1,102,000.
Cost per Vercel edge request call at the time of writing was: $0.000002. For 2,900,000,000 requests this gives us the cost of $5,800.